1. BERT의 개요
가. BERT의 정의
-구글에서 개발한 NLP 사전 훈련 기술로써 기존 앙상블 모델보다 우수한 성능의 모델
나. BERT의 특징
-(트랜스포머 이용), 트랜스포머을 이용하여 구현, 이키피디아와 BooksCorpus와 같은 레이블이 없는 텍스트 데이터로 사전 훈련 모델
-(파인 튜닝), 레이블이 없는 방대한 데이터로 사전 훈련된 모델을 가지고, 레이블이 있는 다른 작업(Task)에서 추가 훈련과 함께 하이퍼파라미터를 재조정
-(인코더 구조 변경), 트랜스포머의 인코더를 다수 쌓아올린 구조
-(양방향 사전 학습), 자연언어 처리 태스크를 교육 없이 양방향으로 사전학습
-(마스크드 언어 모델), 입력 텍스트의 15% 단어를 랜덤으로 마스킹하여 마스킹된 단어를 예측하는 모델
2. BERT의 개념도
가. BERT의 개념도

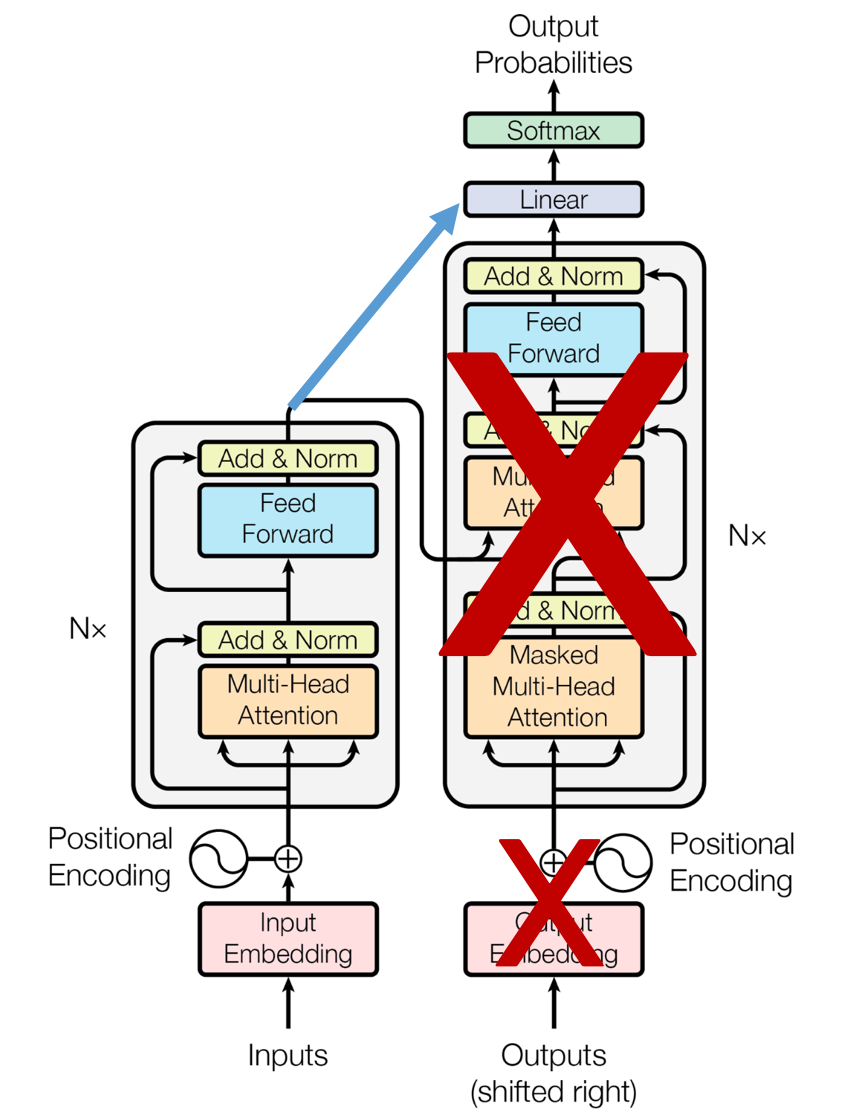

나. BERT의 구성요소
| 구성요소 | 설명 |
| BERT 크기 | -BERT Base (12 Layers) -BERT Large (24 Layers) |
| 입력 임베딩 | -임베딩 층(Embedding layer)를 지난 임베딩 벡터들 |
| BERT 연산 | -하나의 단어가 모든 단어를 참고하는 연산은 BERT의 12개의 층에서 전부 이루어지는 연산 (Base 기준) |
| 출력 임베딩 | -문장의 문맥을 모두 참고한 문맥을 반영한 임베딩 |
'ICT 관련 동향' 카테고리의 다른 글
| BABOK (0) | 2021.05.13 |
|---|---|
| GPT-3 (0) | 2021.05.13 |
| 트랜스포머(Transformer) (0) | 2021.05.12 |
| 희소 표현 & 밀집 표현 & 워드 임베딩 (0) | 2021.05.12 |
| 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq) (0) | 2021.05.12 |




댓글